The Chinese technology company Alibaba has released Qwen3-Omni, a new generative AI model that can process a combination of text, images, audio, and video. The model is notable for its “omni-modal” capabilities and its open-source license, positioning it as a direct competitor to proprietary models from U.S. tech companies like OpenAI and Google.
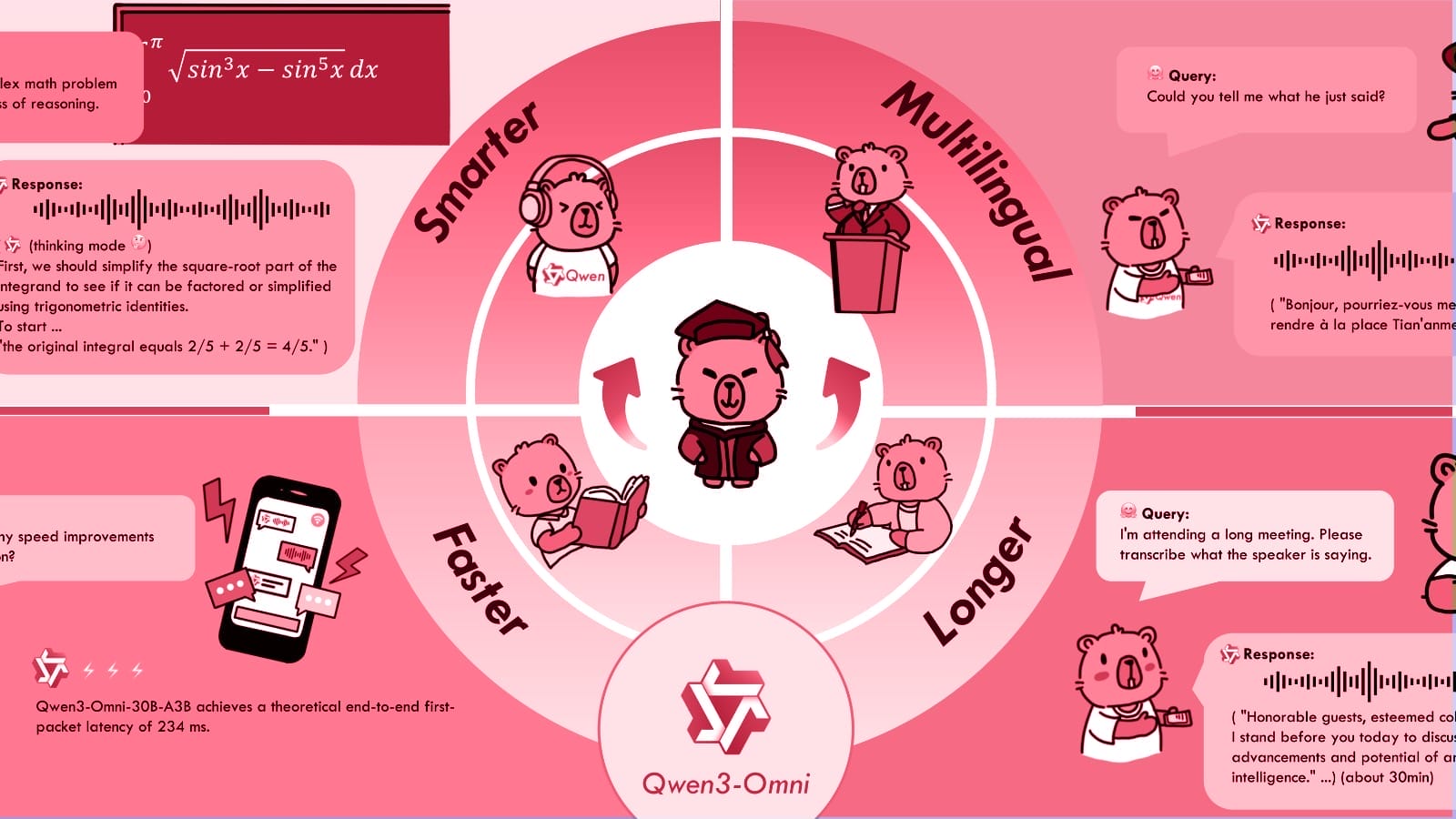
According to information published by Alibaba, Qwen3-Omni is designed as an end-to-end system that can accept inputs from all four modalities and generate responses in both text and natural-sounding speech. This distinguishes it from many existing models. For instance, while Google’s Gemini 2.5 Pro can also analyze video, it is a closed-source product. Google’s open-source Gemma 3n model accepts similar inputs but can only output text.
Alibaba states that Qwen3-Omni’s performance is state-of-the-art across 22 of 36 industry benchmarks for audio and video, without degrading its performance on text and image tasks. The model supports 119 languages for text input, 19 for speech input, and 10 for speech output.
Architecture and Model Versions
The model is built on what Alibaba calls a “Thinker–Talker” architecture. A “Thinker” component, which uses a Mixture-of-Experts (MoE) design for efficiency, is responsible for understanding the multimodal inputs and performing reasoning tasks. A separate “Talker” component then generates the speech output. The company claims this design allows for low-latency, real-time streaming responses.
Alibaba has released three versions of the model to serve different needs:
- Qwen3-Omni-Instruct: The most comprehensive version, containing both the Thinker and Talker to handle all supported inputs and generate both text and audio outputs.
- Qwen3-Omni-Thinking: A version focused on reasoning and analysis. It accepts all input types but only produces text, making it suitable for tasks requiring detailed written explanations.
- Qwen3-Omni-Captioner: A specialized, fine-tuned model designed to generate highly detailed and accurate text descriptions of audio inputs.
Licensing and Availability
Qwen3-Omni is available under the Apache 2.0 license. This permissive open-source license allows developers and businesses to freely download, modify, and deploy the model, including for commercial applications, without paying licensing fees. This approach contrasts with the closed-source, API-access models of competitors like OpenAI’s GPT-4o.
The model is accessible for download on platforms like Hugging Face and GitHub. Alibaba also offers access through its DashScope API, where usage is billed based on tokens. According to pricing information reported by VentureBeat, costs for the API vary by input type, with video and audio being more expensive than text. Text-only output costs approximately $0.96 per million tokens, while combined text and audio output is billed at around $8.76 per million tokens for the audio portion.
Use Cases and System Requirements
The company highlights a wide range of potential applications, from speech recognition and translation to analyzing music, describing video content, and creating interactive audiovisual dialogues. The system’s behavior can be customized using system prompts, allowing developers to adapt it for specific roles, such as a customer service assistant.
Running the model locally requires significant computational resources. Alibaba’s documentation indicates that the base “Instruct” model requires nearly 80 GB of GPU memory to process a 15-second video, with memory requirements increasing with video length. To facilitate use, the company provides pre-configured Docker images and recommends using inference optimization libraries like vLLM for better performance.
Stay up to date
AI for content creation: the latest tools, tips and trends. Every two weeks in your inbox:

