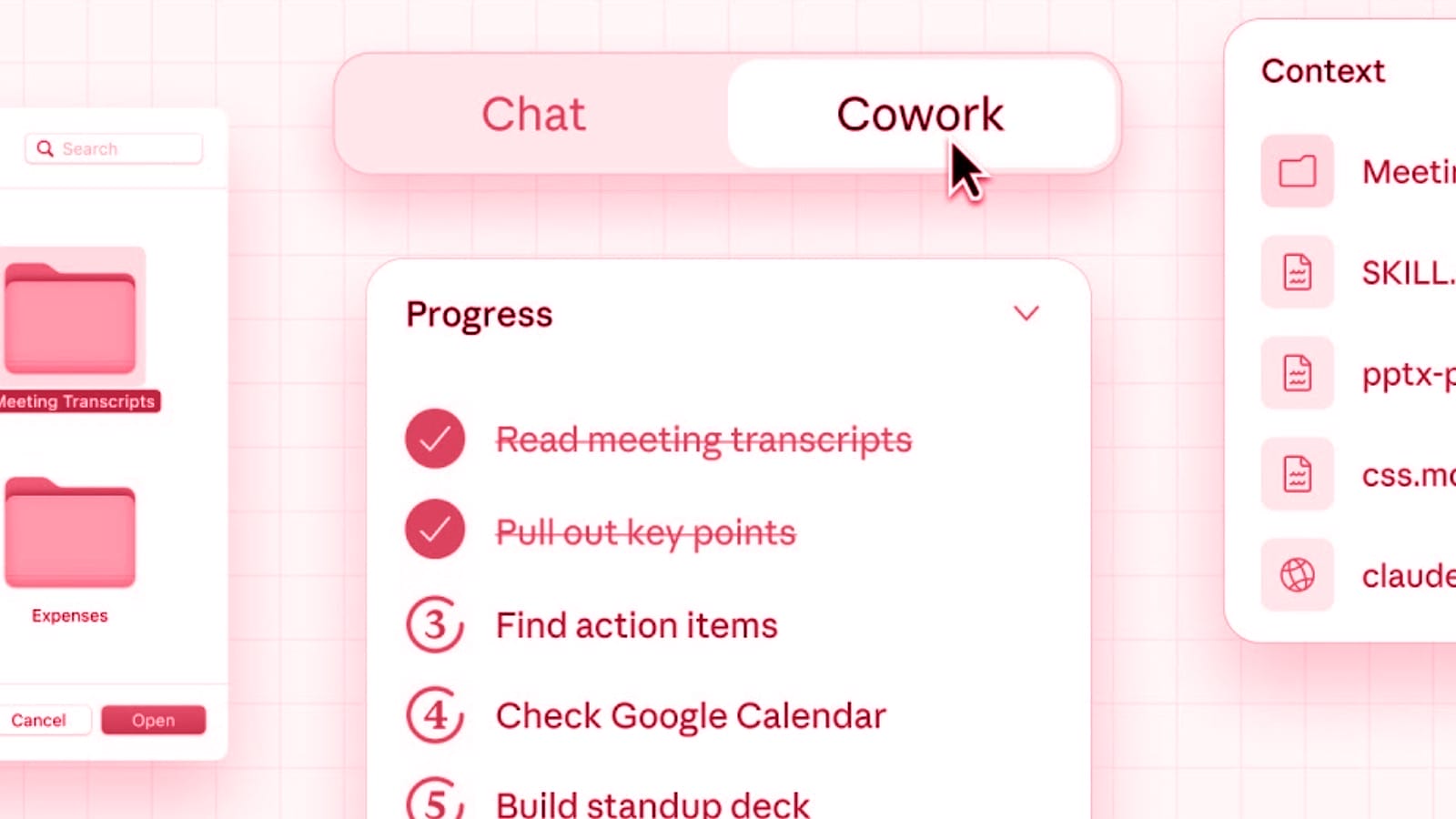
Claude Sonnet 4.6: near-flagship performance at mid-tier pricing

Anthropic has released Claude Sonnet 4.6, a significant upgrade to its mid-tier AI model. The company says it outperforms its predecessor across coding, computer use, long-context reasoning, agent planning, knowledge work, and design. Sonnet 4.6 is now the default model in claude.ai and Claude Cowork and carries the same price as its predecessor, Sonnet 4.5, …