Google’s free TurboQuant algorithm can slash AI costs significantly
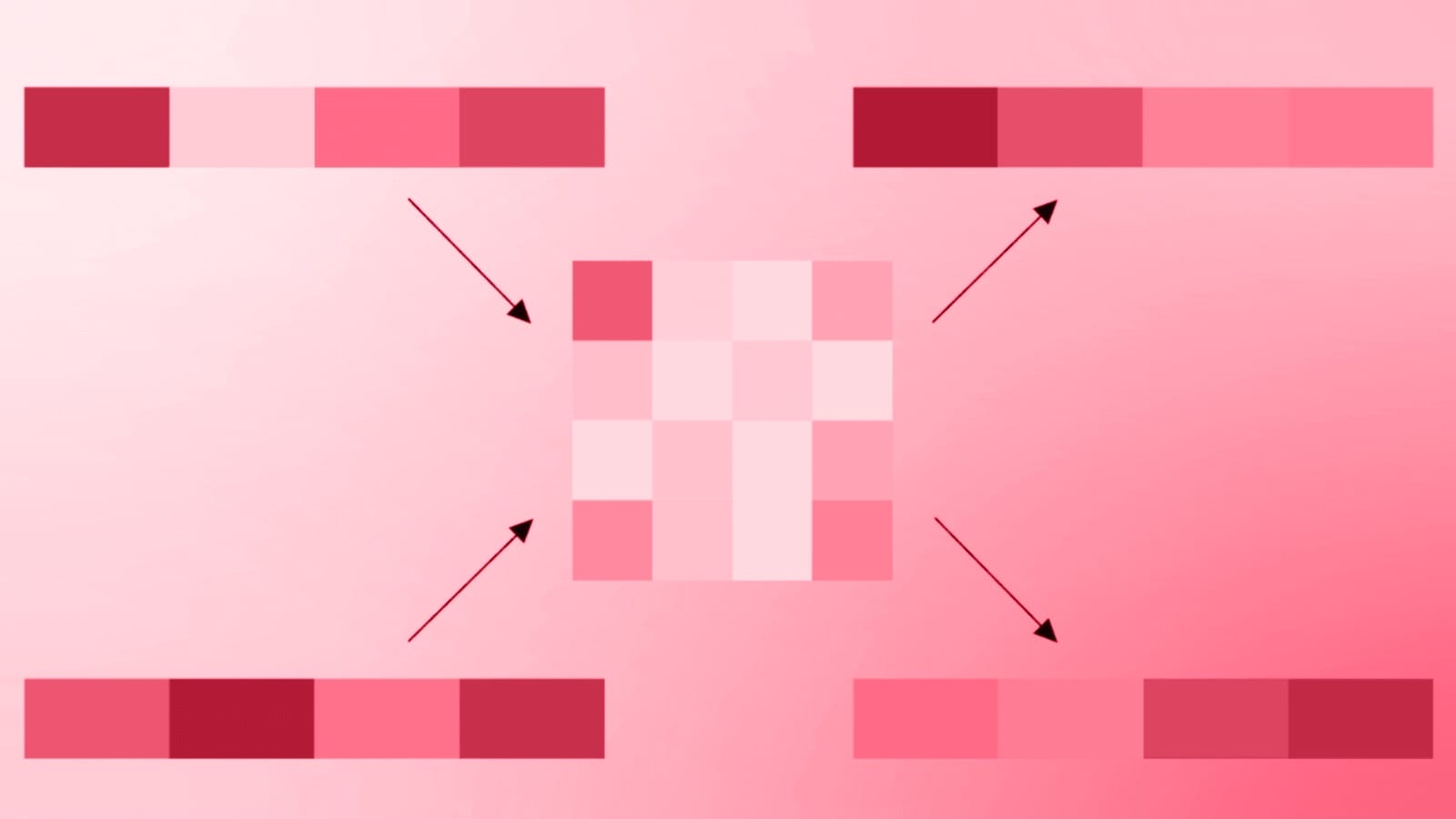
Google Research has released TurboQuant, a new compression algorithm designed to reduce the memory demands of large language models. The company says it can shrink a model’s key-value cache by at least six times and speed up a core processing step called attention computation by up to eight times, all without retraining the model or …



